Contents
Add paths
clc
clear variables;
addpath('C:\MATLAB\mTRF_1.6');
addpath C:\MATLAB\fieldtrip-20170801\fieldtrip-20170801
ft_defaults
Initialize some variables
fs = 250;
nCh = 64;
sCh = 65;
bpF = [4 8];
bpF_o = 2;
trilen = 60;
lambda = 256;
intWin = [-100 350];
C1 = [0.8500, 0.3250, 0.0980];
C2 = [0, 0.4470, 0.7410];
Import data and visualize
load S04_raw;
cfg = [];
cfg.channel = 1:nCh;
eeg = ft_selectdata(cfg,data);
cfg.channel = sCh;
stim = ft_selectdata(cfg,data);
cfg = [];
cfg.ylim = [-10 10];
cfg.blocksize = 20;
cfg.continuous = 'yes';
cfg.viewmode = 'vertical';
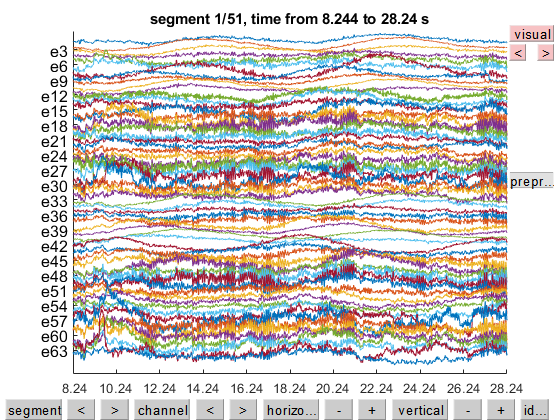
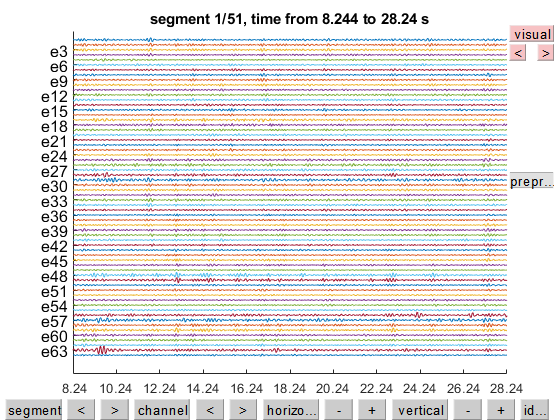
ft_databrowser(cfg,eeg);
figure;
cfg = [];
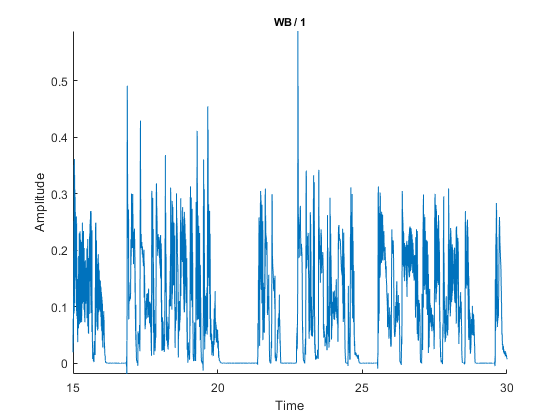
cfg.xlim = [15 30];
cfg.graphcolor = C2;
ft_singleplotER(cfg,stim);
ylabel('Amplitude'); xlabel('Time')
cfg = [];
cfg.bpfilter = 'yes';
cfg.bpfreq = bpF;
cfg.bpfiltord = bpF_o;
cfg.reref = 'yes';
cfg.refchannel = 'all';
eeg = ft_preprocessing(cfg,eeg);
cfg = [];
cfg.ylim = [-10 10];
cfg.blocksize = 20;
cfg.continuous = 'yes';
cfg.viewmode = 'vertical';
ft_databrowser(cfg,eeg);
the call to "ft_selectdata" took 0 seconds
the call to "ft_selectdata" took 0 seconds
the input is raw data with 64 channels and 1 trials
detected 0 visual artifacts
the call to "ft_singleplotER" took 0 seconds
the call to "ft_selectdata" took 0 seconds
preprocessing
preprocessing trial 1 from 1
the call to "ft_preprocessing" took 3 seconds
the input is raw data with 64 channels and 1 trials
detected 0 visual artifacts
TRFs. Step 1: Encoding Models
data = eeg.trial{1};
stim = stim.trial{1};
data(sCh:end,:) = [];
nTri = floor((length(data)/fs) / trilen);
data = data(:,1:nTri * trilen * fs);
data = reshape(data,[nCh, trilen * fs, nTri]);
stim = stim(:,1:nTri * trilen * fs);
stim = reshape(stim,[1,trilen * fs, nTri]);
dat = []; sig = []; sig2 = [];
for tr = 1:size(stim,3)
dat{tr} = zscore(data(:,:,tr)');
sig{tr} = zscore(squeeze(stim(:,:,tr))');
sig2{tr} = flipud(zscore(squeeze(stim(:,:,tr))'));
end
trfsF = []; cF = [];
trfsR = []; cR = [];
for tr = 1:length(sig)
[trfsF(tr,:,:),t,cF(tr,:)] = mTRFtrain(sig{tr},dat{tr},fs,1,intWin(1),intWin(2),lambda);
[trfsR(tr,:,:),t,cR(tr,:)] = mTRFtrain(sig2{tr},dat{tr},fs,1,intWin(1),intWin(2),lambda);
end
modlF = mean(trfsF,1);
modlR = mean(trfsR,1);
cF = mean(cF,1);
cR = mean(cR,1);
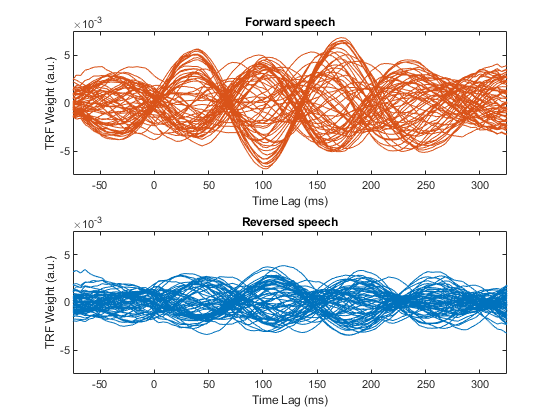
figure;
subplot(2,1,1)
plot(t,squeeze(modlF),'color',C1)
axis([-75 325 -.0075 .0075])
xlabel('Time Lag (ms)'); ylabel('TRF Weight (a.u.)');
title('Forward speech')
subplot(2,1,2)
plot(t,squeeze(modlR),'color',C2)
xlabel('Time Lag (ms)'); ylabel('TRF Weight (a.u.)');
title('Reversed speech')
axis([-75 325 -.0075 .0075])
set(gcf,'color','w');
predF = []; predR = [];
rF = []; rR = [];
for tr = 1:length(sig)
[predF(:,:,tr),rF(tr,:)] = mTRFpredict(sig{tr},dat{tr},modlF,fs,1,intWin(1),intWin(2),cF);
[predR(:,:,tr),rR(tr,:)] = mTRFpredict(sig2{tr},dat{tr},modlR,fs,1,intWin(1),intWin(2),cR);
end
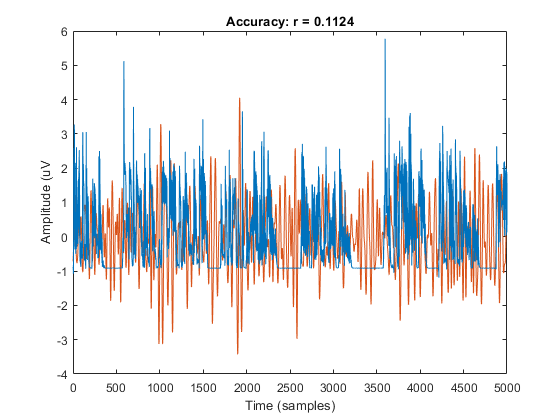
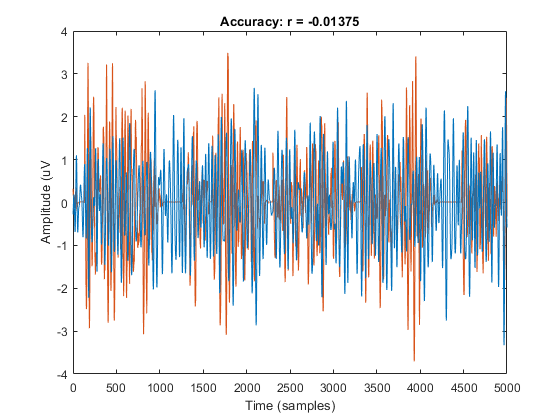
figure; plot(zscore(squeeze(predF(2e3:7e3,1,1))),'color',C1); hold on;
plot(zscore(squeeze(dat{1}(2e3:7e3,1))),'color',C2)
xlabel('Time (samples)'); ylabel('Amplitude (uV');
title(['Accuracy: r = ' num2str(rF(1,1))]);
xlim([0 5e3])
avAcc = [mean(mean(abs(rF))) mean(mean(abs(rR)))];
disp(['Average Encoding Accuracy for Forward Speech: r = ' num2str(avAcc(1))])
disp(['Average Encoding Accuracy for Reverse Speech: r = ' num2str(avAcc(2))])
Average Encoding Accuracy for Forward Speech: r = 0.045845
Average Encoding Accuracy for Reverse Speech: r = 0.034466
Step 2: Decoding Models
disp('Running decoding models. This process is slower than for encoding.')
trfsF = []; trfsR = [];
for tr = 1:length(sig)
disp(['Decoding Model. Trial: ' num2str(tr) ' of ' num2str(length(sig))])
[trfsF(:,:,tr),t,cF] = mTRFtrain(sig{tr},dat{tr},fs,-1,intWin(1),intWin(2),lambda);
[trfsR(:,:,tr),t,cR] = mTRFtrain(sig2{tr},dat{tr},fs,-1,intWin(1),intWin(2),lambda);
end
modlF = mean(trfsF,3);
modlR = mean(trfsR,3);
cF = mean(cF,2);
cR = mean(cR,2);
predF = []; predR = [];
rF = []; rR = [];
for tr = 1:length(sig)
[predF(:,tr),rF(tr,:)] = mTRFpredict(sig{tr},dat{tr},modlF,fs,-1,intWin(1),intWin(2),cF);
[predF(:,tr),rR(tr,:)] = mTRFpredict(sig2{tr},dat{tr},modlR,fs,-1,intWin(1),intWin(2),cR);
end
figure; plot(zscore(squeeze(predF(5e3:10e3,2))),'color',C1); hold on;
plot(zscore(sig{2}(5e3:10e3)),'color',C2)
xlabel('Time (samples)'); ylabel('Amplitude (uV');
title(['Accuracy: r = ' num2str(rF(1))]);
xlim([0 5e3])
avAcc = [mean(abs(rF)) mean(abs(rR))];
disp(['Average Encoding Accuracy for Forward Speech: r = ' num2str(avAcc(1))])
disp(['Average Encoding Accuracy for Reverse Speech: r = ' num2str(avAcc(2))])
Running decoding models. This process is slower than for encoding.
Decoding Model. Trial: 1 of 16
Decoding Model. Trial: 2 of 16
Decoding Model. Trial: 3 of 16
Decoding Model. Trial: 4 of 16
Decoding Model. Trial: 5 of 16
Decoding Model. Trial: 6 of 16
Decoding Model. Trial: 7 of 16
Decoding Model. Trial: 8 of 16
Decoding Model. Trial: 9 of 16
Decoding Model. Trial: 10 of 16
Decoding Model. Trial: 11 of 16
Decoding Model. Trial: 12 of 16
Decoding Model. Trial: 13 of 16
Decoding Model. Trial: 14 of 16
Decoding Model. Trial: 15 of 16
Decoding Model. Trial: 16 of 16
Average Encoding Accuracy for Forward Speech: r = 0.11755
Average Encoding Accuracy for Reverse Speech: r = 0.060606